本篇要介紹機器學習裡面最簡單的分類演算法: K最近鄰演算法, 簡稱KNN
同時也介紹R統計程式碼如何展示KNN演算法
※※※K 最近鄰法的觀念※※※
K最近鄰法又稱K最近鄰居法
為了要體會這方法的精神, 我們首先要來望文生義一下
「K最近鄰法」的英文很直白, 就是K-The Nearest Neighbor, K個最相近的鄰居!!!,
夠直白吧!!!
這時腦袋就出現 「孟母三遷」 跟 「進朱者赤, 近墨者黑」
KNN就是利用同類相吸的概念發展起來的方法
假設有一筆新進的數據點, A,
A同樣有收集相關的預測變數
這時我們就可以依據A的預測變數, 衡量/找出與他最相近的K個數據集{P1, P2,..., PK}
這時要注意一件事, 這K個最接近A的鄰居, 他們已經各自分好類了!!!
所以, 想法很簡單, 我們就來看看最接近A點的鄰居, 都被分到哪些類別?
假設 這P個鄰居, 共分成C類, {Type1, Type2, ..., TypeC}
再假設, 出現的比例分別是, R1, R2, ..., RC,
其中 R1+R2+...+RC=100%.
我們只要看看, 『與A點最相近的鄰居, 被歸類到某一類的比例最高, 那A點就是那一類了!!!!』
有了以上的概念, 我相信, 下面這一張圖, 你一定是一看就懂
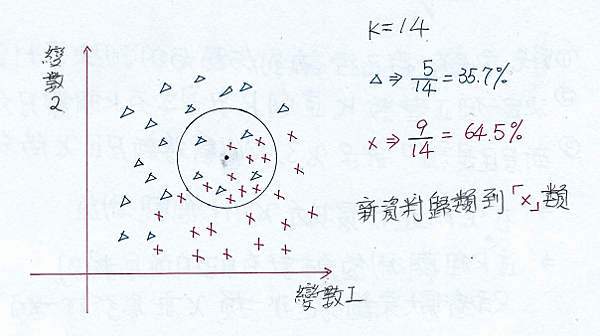
圖中的圓圈圈就是以新資料為中心, 然後找到14個最近鄰的數據資料, 然後計算圓缺內的分類比例.
※※※K 最近鄰法的注意事項※※※
可以注意到,
1.KNN演算法適合多分類的反應變數, 並不限制只是分類Binary data.
2.KNN演算法需要事先知道訓練集的分類答案, 不然該方法無法知道新進的數據該分到哪一類.
這點與其他分類法很不同. KNN不計算「訓練錯誤率」, KNN需要訓練集的分類做分類依據.
3.因為KNN演算法是依據離A點最近的「距離」, 來評估A點要分到哪一類
所以預測變數的尺度(Scale)會大大影響結果.
為了公平起見, 建議把預測變數都標準化, 這樣同一變數內就都統一了相對的距離了
可以利用R程式碼 scale() 函數做到這件事.
4.針對分類類別是偶數, 導致可以有相同分類比例出現的問題, 這時可以選取K為奇數, 就可避免這問題了.
※※※K 最近鄰法在R中的程式碼※※※
這篇範例是關於「大型敞篷車是否加買保險的問題」
保險公司希望可以找到加保意願高的潛在客戶
如此公司可以省去一些推銷資源, 提高賣保單的效率
保險公司收集客戶(5822筆數據)的相關資料(86個變數), 資料中包含一個是否購買的變數(第86個變數)「Purchase」= {Yes, No}
要使用KNN演算法, 要給3個集合與K值
這3個集合分別是:
訓練資料集的預測變數:用來訓練的預測變數
訓練資料集的分類變數:用來對應上述的預測變數的已分類反應變數, 這樣找鄰居然才能算分類比例
測試資料集的預測變數:用來測試的預測變數. 每一個測試變數都會被當作新的變數
K值就是要看有多少鄰居要找進來算比例.
如果是使用訓練與測試82法則, 則取訓練筆數:測試筆數=4650:1172
以下就進行KNN演算法:
#載入ISLR資料庫, 我們需要的資料在這資料庫裏面
library(ISLR)
#看一下"Caravan",大型敞篷車投保資料集,的樣本數有多少?(5822),收集的變數有幾個?(86)
dim(Caravan)
#可以看一下收集的86個變數名稱. 注意到最後一個是反應變數Purchase
names(Caravan)
#先看一下變數的敘述統計量
summary(Caravan)
#計算會購買保險的比例是多少?(5.977%)
table(Caravan$Purchase)/dim(Caravan)[1]
#除分類變數外,將其餘預測變數進行資料標準化
S.Caravan<-scale(Caravan[,-86])
#進行資料分割
train.index<-1:4650
train.X<-S.Caravan[train.index,-86]
train.Y<-Caravan[train.index,+86]
test.X<-S.Caravan[-train.index,-86]
test.Y<-Caravan[-train.index,+86]
#下載含有KNN的package
library(class)
#呼叫knn函數, 關鍵參數有train, test, cl 與 k
KNN_1<-knn(train=train.X, test=test.X, cl=train.Y, k=1)
#建立Confusion Matrix
Confusion.matrix<-table(Truth=test.Y,Prediction=KNN_1)
Confusion.matrix
#求測試正確與錯誤率, 分別是88.14%與11.86%
sum(diag(Confusion.matrix))/sum(Confusion.matrix)
1-sum(diag(Confusion.matrix))/sum(Confusion.matrix)
#但是, 本來買保險的人只有6%, 所以這樣的正確率, 說實在, 差強人意啊
#同時, 我們更關心的是, 我們預測會買保險的客戶, 實際上真的買了保險的比例, 有8.1%
#結果差強人意
Confusion.matrix[2,2]/sum(Confusion.matrix[,2])
#找尋好的K值
k<-1:50
Rate<-numeric(length(k))
for(i in k)
{
set.seed(1)
KNN_k<-knn(train=train.X, test=test.X, cl=train.Y, k=i)
Confusion.matrix<-table(Truth=test.Y,Prediction=KNN_k)
ifelse(sum(Confusion.matrix[,2])!=0,
Rate[i]<-Confusion.matrix[2,2]/sum(Confusion.matrix[,2]),
Rate[i]<-0)
print(i)
}
Rate
#圖示法, 展示最佳K值
plot(k,Rate,type="l",lty=2,lwd=2,col=3,ylab="命中率",xlab="最近鄰數量(k)")
points(k,Rate,pch=19,lwd=2)
圖形如下所示:

可以清楚看到, 最近鄰數取為13時, 拜訪客戶中, 有超過30%的客戶會購買保險, 這比隨機地無目的拜訪客戶的6%成功率大大提升不少!!!!
所以收集客戶的預測變數資料後, 可使用KNN事先預測該客戶是否會購買保險, 針對預測為會購買保險的客戶進行拜訪, 我們相信成功率會大大提升的!!!
KNN的概念與應用就介紹到這邊, 這組資料還可以使用邏輯斯迴歸(Logistic Regression)做分類, 請期待Logistic Regression的文章

 留言列表
留言列表

